文字识别
该插件的应用方面包括:
- 识别舞台图像或网络URL中的图像,并返回识别到的文字内容
快速开始
目前区别了两种模式的文字识别,包括
标准和精准两种,他们之间支持的语种和调用积分数也不同,一般来说中文英文的识别是标准版即可满足需求。以下案例使用舞台图像进行讲解,你也可以夹在 视频侦测 扩展使用摄像头图像进行识别,效果一样。
标准文字识别结果
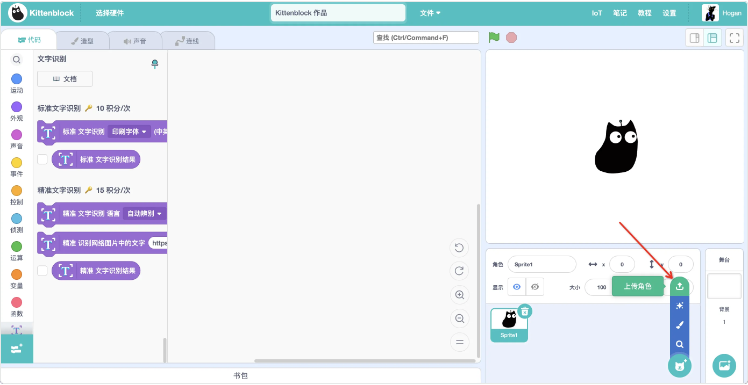
- 下载我们提供文字素材图片,通过上传角色导入

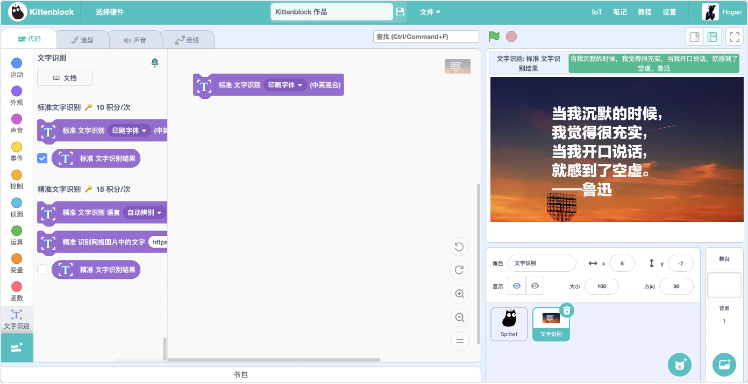
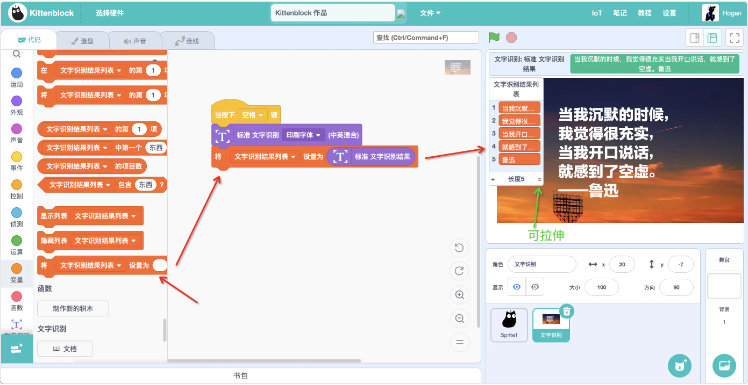
- 导入后,我们将文字识别结果返回值积木前的checkbox勾选上,这样舞台就可以看到返回值内容,点击积木运行一次识别查看返回结果
- 识别的结果其实是一个列表,列表的规则是根据识别内容的行数,自上到下来划分。我们首先新建一个列表(定个好理解的名字)
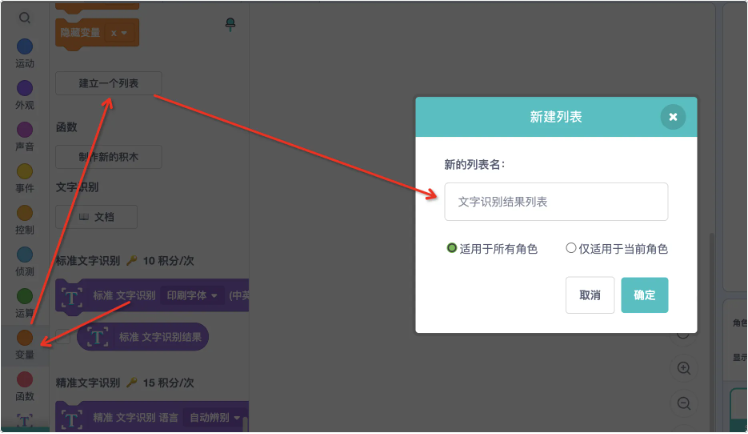
- 将文字识别结果赋值给这个列表,我们可以看到它将识别文字的不同行依次划分在列表元素中。
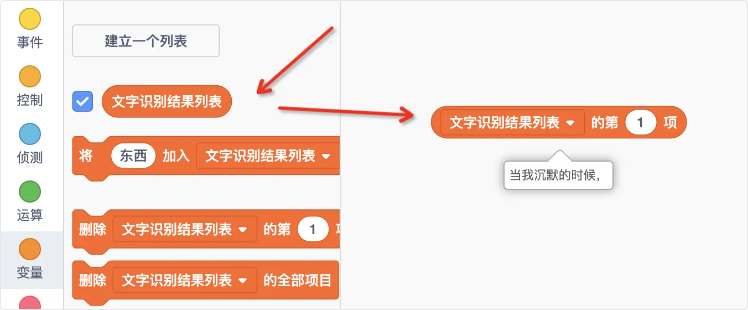
- 我们可以通过元素位置去取对应行的文字
- 如果想将所有文字串起来,则可以通过一个简单的循环运算完成。
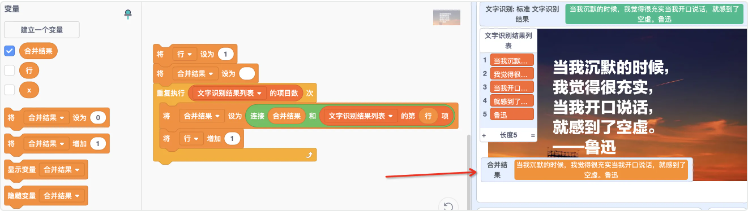
- 首先创建2个变量分别命名行和合并结果
- 让循环执行列表的项目数,5行即5次
- 从第一行开始取列表的值,并用上一次的
合并结果与之相连赋给这一次的合并结果 - 完成5次循环后,5行的数据被连接到了一起,此时你就拥有了一个连续的字符串内容。方便用于语音朗读,或者在其他需要的地方进行展示。