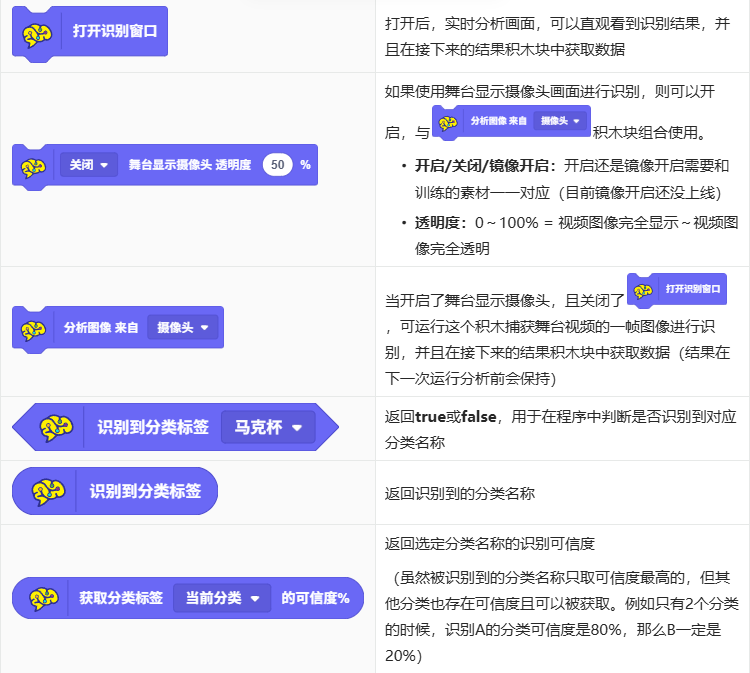
图像分类
1.功能简介
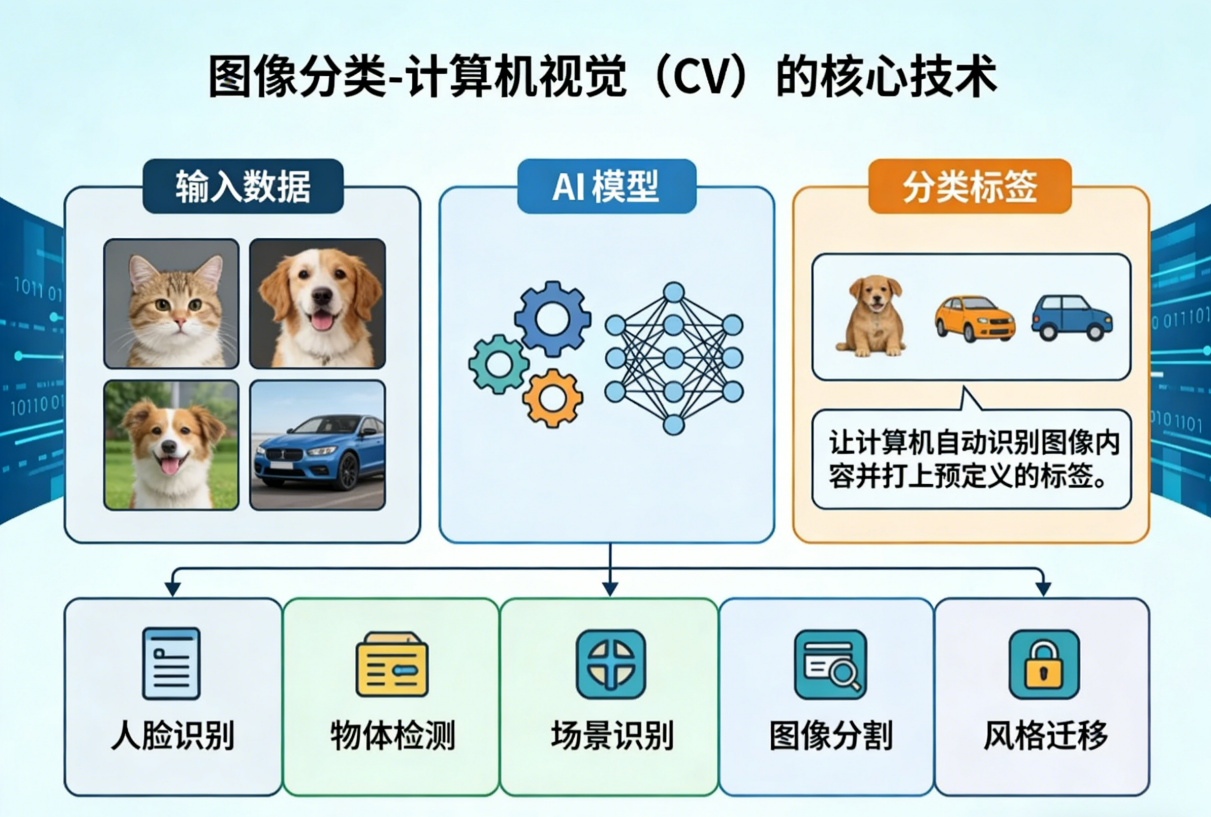
图像分类(Image Classification)是计算机视觉领域最基础且应用最广的技术之一,是利用人工智能算法,让计算机自动理解图像内容并将其归入预设类别的技术。简单来说,它就是让计算机“观看”一张图片,并根据其视觉内容自动打上预定义的“标签”或归入特定的“类别”。
图像分类在我们日常生活中无处不在,以下是一些典型例子:
- 内容安全与审核:在社交媒体、网盘或在线社区中,自动识别上传的图片是否包含“暴力”、“色情”或“不适宜”内容,并将其过滤或标记。
- 医疗影像诊断辅助:帮助医生初步分析医学影像,例如将X光、CT或病理切片图片分类为“正常”、“疑似病变”或“明确异常”,常用于肺炎、癌症筛查等。
- 自动驾驶感知:车辆上的摄像头实时识别道路场景中的物体,并将其归为“行人”、“车辆”、“交通标志”、“车道线”等类别,是决策系统的基础。
- 电商与零售:电商平台自动识别用户上传的商品图片,将其分类到“服装”、“电子产品”、“家居”等正确的品类中,便于搜索和推荐。
- 农业生产监控:利用无人机或田间摄像头拍摄的图片,自动识别作物生长状况,分类为“健康”、“缺水”、“遭遇虫害”或“发生病害”,实现精准农业。
2.核心原理
通过我们的图像识别功能,你可以轻松训练出一个专属的“视觉理解模型”,赋予项目看懂图片的能力。该功能通过深度卷积神经网络的底层能力实现图像分类,其核心原理是迁移学习。
需要注意的是,当你提供少量的图片样本进行训练时,该功能并不是从零开始学习识别每一个像素,而是在模型已有的强大视觉认知基础上,快速建立“你提供的特定图片特征”与“你定义的分类标签”之间的新关联。这使得你通常只需几十到几百张图片,就能得到一个针对你任务的高准确度模型。
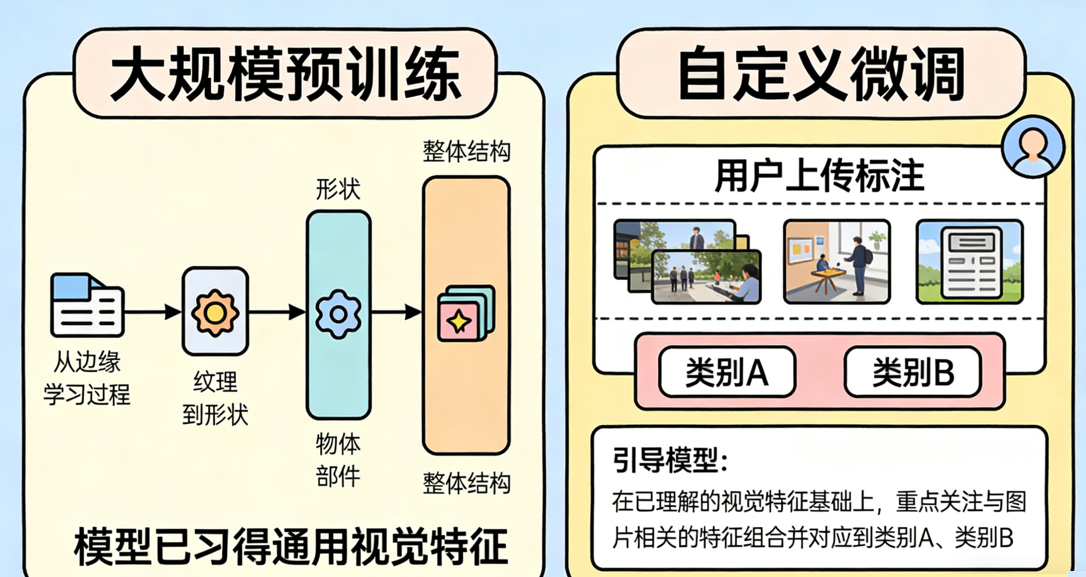
其核心在于使用一个已经在大规模通用图像数据上训练好的“预训练模型”。这个模型在训练过程中,已经自动学习了如何从图片中提取从简单到复杂的通用特征。
- 大规模预训练:模型已习得通用的视觉特征,例如从边缘、纹理,到更复杂的形状、物体部件乃至整体结构。
- 自定义微调:当你上传并标注自己的图片时,你实际上是在引导模型:“在你已理解的各种视觉特征基础上,重点关注与我这些图片相关的特征组合,并分别对应到我定义的类别A、类别B上。”
3.功能加载
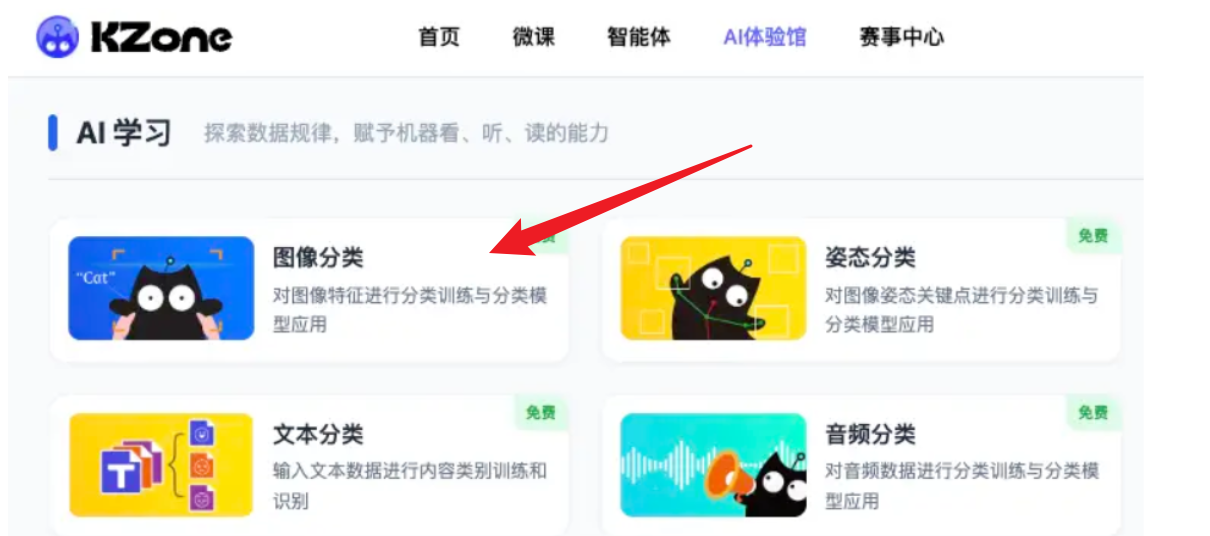
如果仅需体验模型训练与测试,可通过KZone人工智能教育平台进入,在【AI体验馆】下的【AI学习】板块中找到【文本分类】的功能,点击后进入即可,跳转链接如下:
https://kzone2.kittenbot.cn/ai-lab
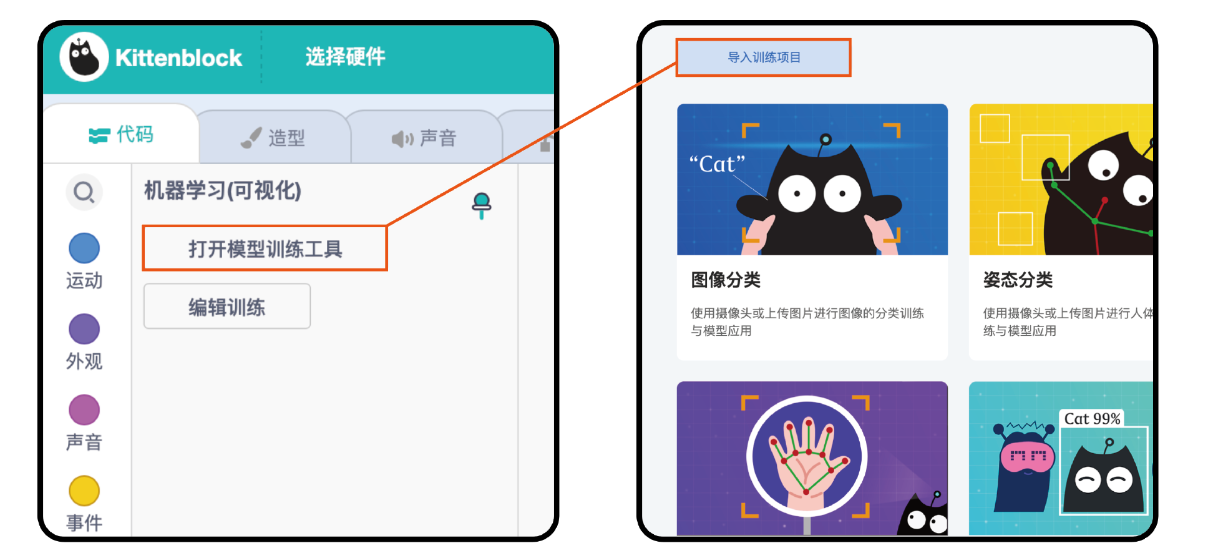
如果想在Kittenblock图形化编程平台中进一步使用训练好的模型,则通过左下角的【添加拓展】进入拓展界面,在【角色拓展】中添加【可视化机器学习】。添加后回到编程界面,在相关插件下点击【模型训练工具】即可选择【图像分类】,Kittenblock跳转链接如下:
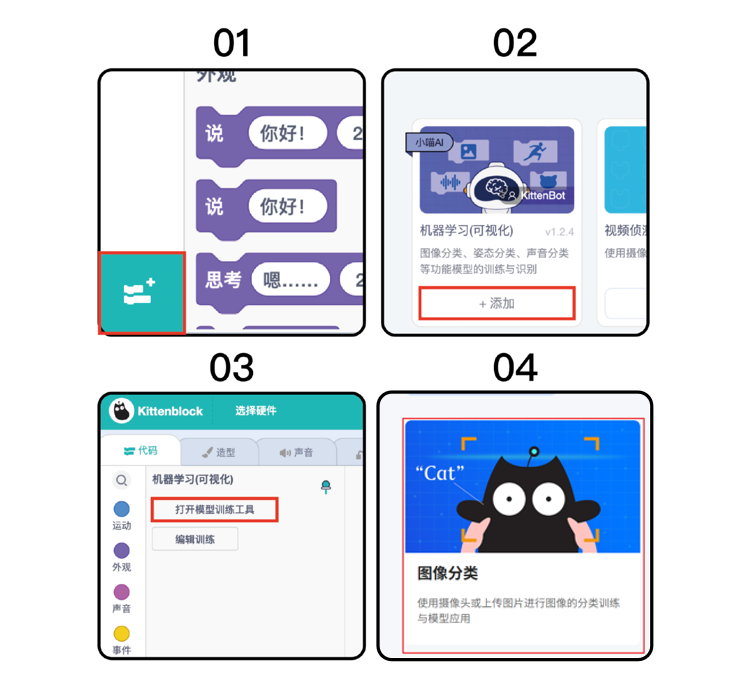
4.实验流程
a.收集与分类
首先,你需要定义想要识别的“标签”,也就是创建不同的“类”(Classes)。随后为每个类添加图片样本。例如,如果你想做一个奥特曼分类器,你会创建两个类:
- Class 1 :不同的A奥特曼图片
- Class 2 :不同的B奥特曼图片
注意:您可以使用摄像头拍照与上传图片两种方式来添加素材。每个类提供的样本越多、越多样化、越有代表性,模型的准确度就越高。
随机进入一个 图像分类 的界面,来大致认识一下数据收集和训练的界面功能
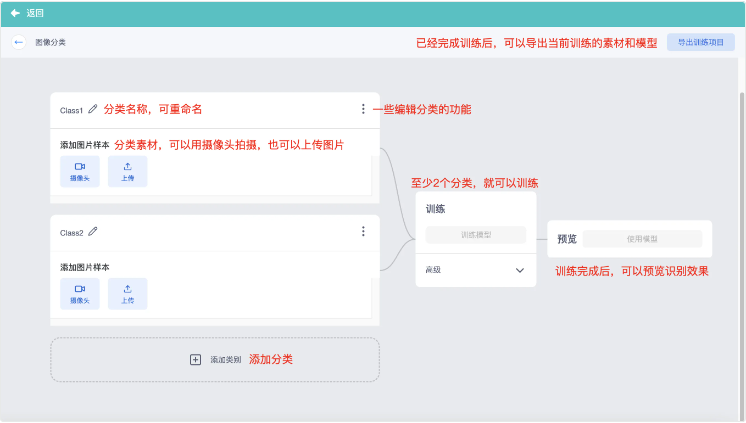
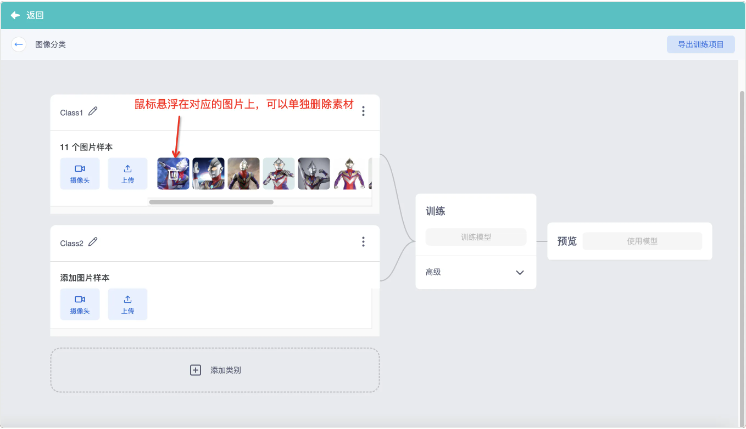
- 如果你选择从本地图片上传素材,可以多选图片一起上传,但需要注意,图片的尺寸最好是1:1,否则上传后也会被压缩到1:1
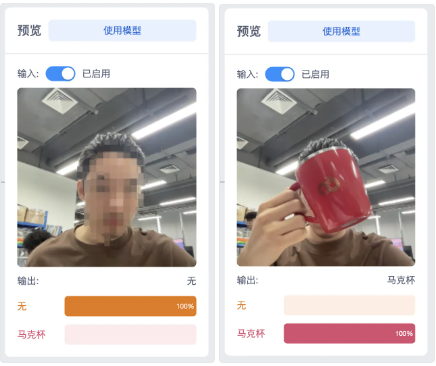
- 如果您是使用摄像头拍摄素材,那么我们来尝试一个最简单的,只有2个分类(空状态和马克杯)的项目带同学们快速了解应用过程
首先理清我们需要制作的,是一个可以分辨是否有马克杯的模型,1个分类叫做 “无”,另一个叫做 “马克杯”,接下来使用摄像头开始采集数据
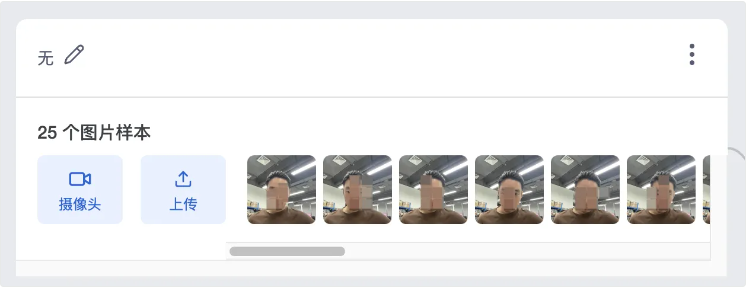
采集分类“无”,尽量让采集的素材画面统一,但内容物可以状态随机一些
所谓的画面统一,内容物状态可以随机一些,大概理解为:
通过大量的素材,让机器搞清楚规律,类比人类多次看到同一个场景,会渐渐熟悉。即使这个场景画面里有些东西比较杂乱,甚至可能每次摆放的位置角度不完全一样,亦或者有人在背景里,每次的姿势和角度也都不太一样,但只要这个素材录入足够多,机器就可以大概认识这个场景,从而与其他的分类做出差异辨认。
- 采集分类“马克杯”,我会在同一个场景下,让马克杯出现在画面中,通过
内容物的状态可以随机一些这个规则,我们录制的马克杯可以远、可以近,可以角度不一致。
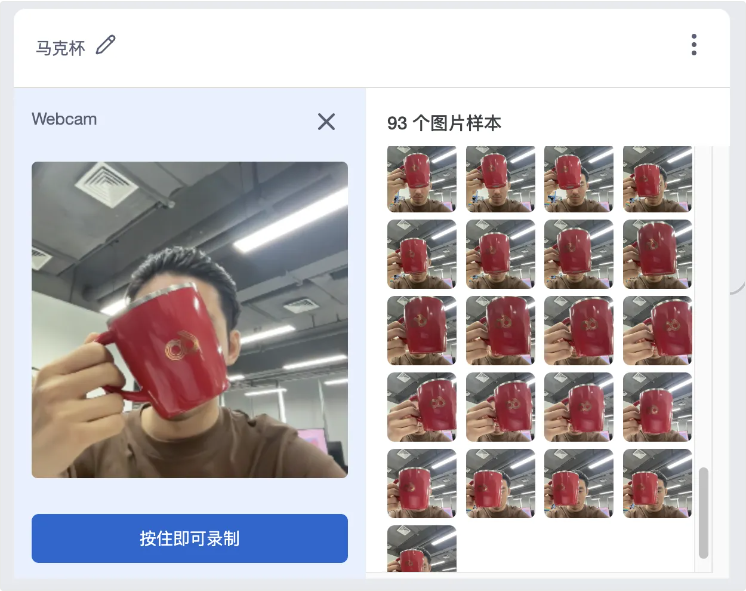
- 这样我们就拥有了2个分类,且有足够的素材,可以开始训练了(素材数量建议每种分类10个以上)
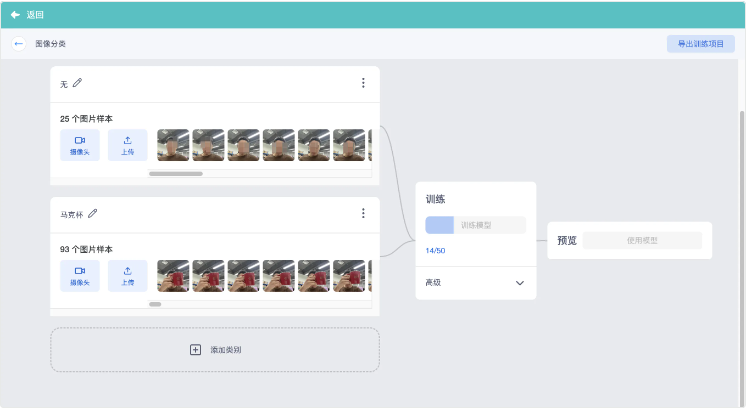
b.模型训练
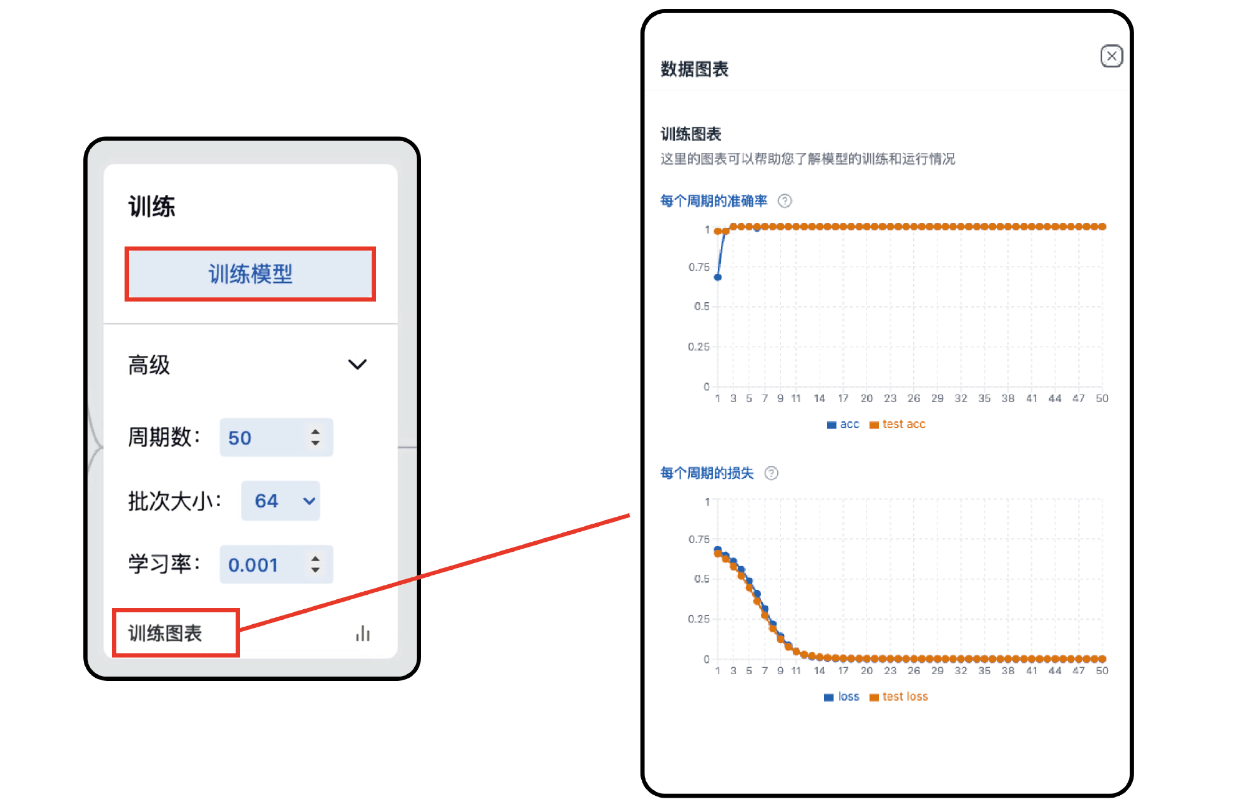
点击【模型训练】后,系统将利用本地算力(CPU/GPU)进行实时的特征提取与参数调优。CNN自动提取图像中的重要特征,通过反复迭代优化,在后台构建出一套专属的分类逻辑,确保能够快速、准确地识别您定义的各种类别。点击【数据图表】,可以查看学习数据。
- Epochs(周期数):模型完整查看一遍所有数据次数。
- Batch Size(批次大小):每次学习时处理的数据量。
- Learning Rate(学习率):模型在每次更新参数时步进的幅度
c.测试与调整
训练完成后,你可以在上传一张图片或者打开摄像头测试模型训练效果。
- 反馈:模型会给出一个置信度评分(例如:100%无 ,0% 马克杯)。
- 调优:如果预测错了,你需要检查是不是数据量不够,或者两类样本中有太多相似的图片。
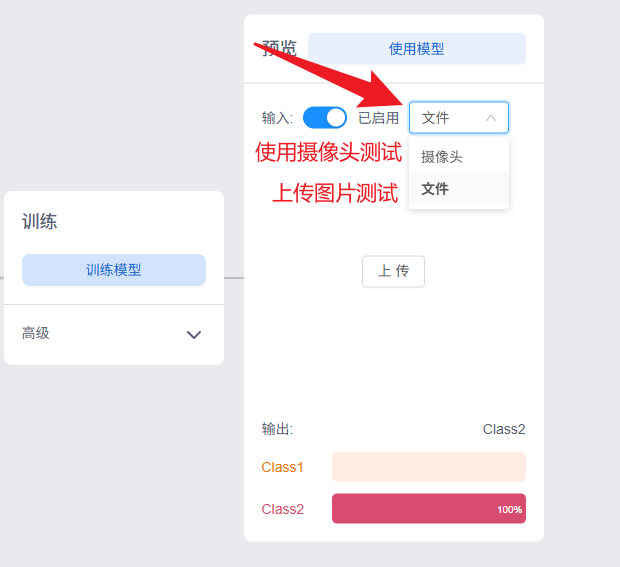
- 使用摄像头测试 - 随着素材的数量多少,训练可能会花费一些时间,完成训练后在右侧可以体验训练识别结果
d.导出与应用
训练好的模型可以直接与积木块或代码逻辑挂钩,通过简单的代码调用这个模型。
- 应用: 当模型识别出特定的类别时,你可以触发后续动作。比如识别到 ‘马克杯’ 的时候说“马克杯”,识别到 ‘无’ 的时候说“无”
无论你是在KZone训练还是在Kittenblock训练,都可以直接下载模型,方便下一次使用。
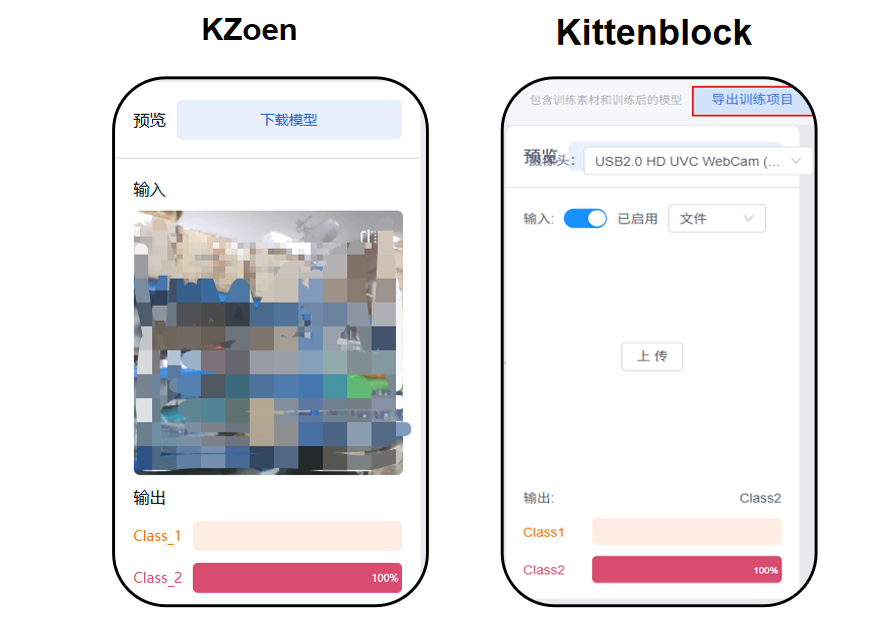
在Kittenbkock中,在相关插件下点击【模型训练工具】即可选择【导入训练项目】,此时可导入之前下载好的模型。如果需要调整模型,则可以点击【编辑训练】
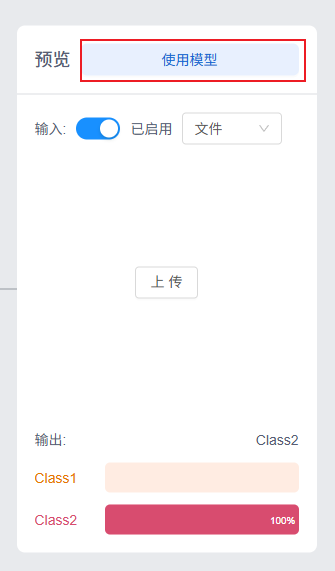
模型导入后或者你是在Kittenblock中直接训练完模型,则可以点击【使用模型】,跳转编程界面。
图像分类的相关积木及其作用如下:

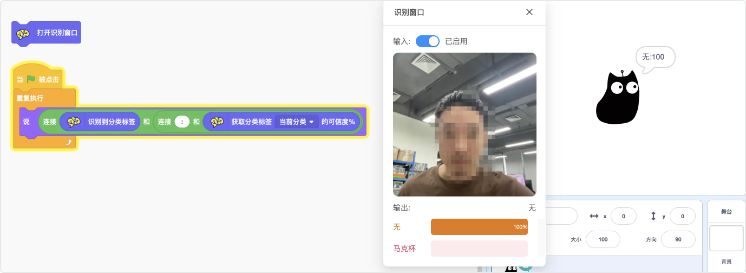
基础应用1:
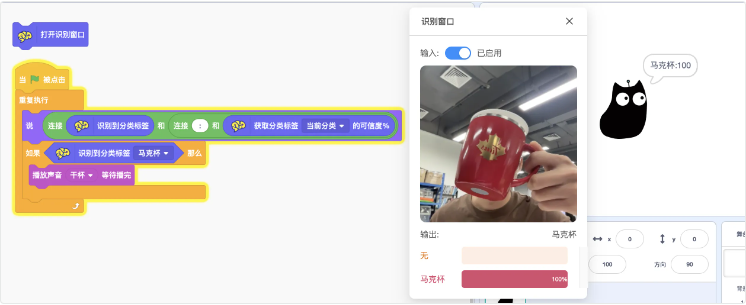
首先打开识别窗口,并搭建一个最基础的识别程序:让小猫说出识别结果和可信度
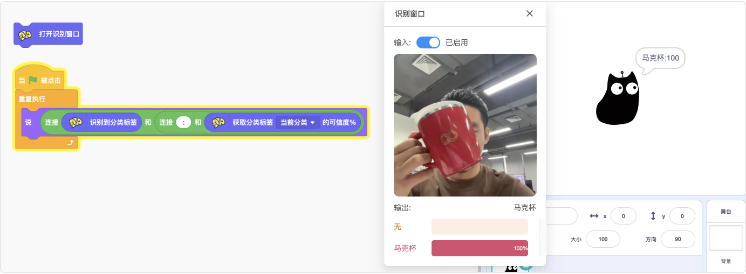
基础应用2:
接下来我们不仅要显示,还要把它与角色的其他功能联动。例如希望别到马克杯的时候播放声音:“干杯”。那么现在先来录制一个“干杯”的声音。
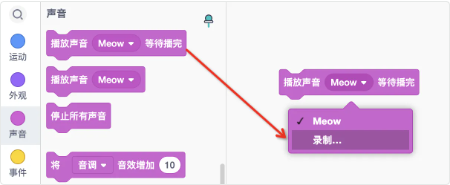
录制后,截取有效片段后保存
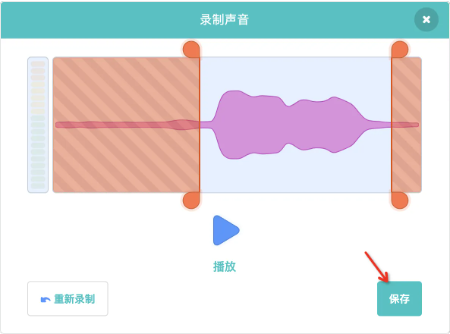
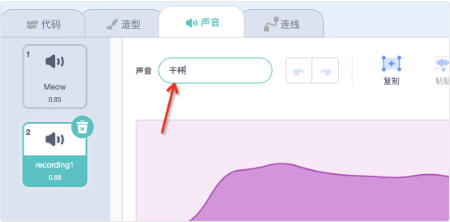
可以修改声音的名称,这样比较直观。修改完后回到代码区开始编写程序
增加1个如何..那么..判断语句来完成这个识别到马克杯播放“干杯”音效的效果。
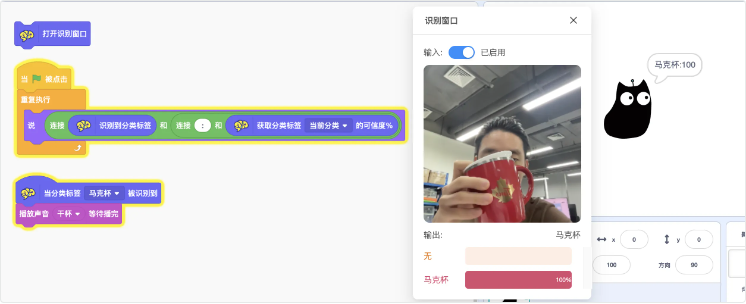
- 但是你会发现当一直识别到马克杯的时候,干杯音效持续播放,未免有些傻呼呼,那么如果要让它第一次识别到马克杯时播放且只播放一次呢?这可能需要引入变量来控制这个状态,这很麻烦,所以这个时候帽子事件积木块就发挥作用了,这样就能够只在识别结果改变的那一刻触发,而不会持续播放“干杯”啦~
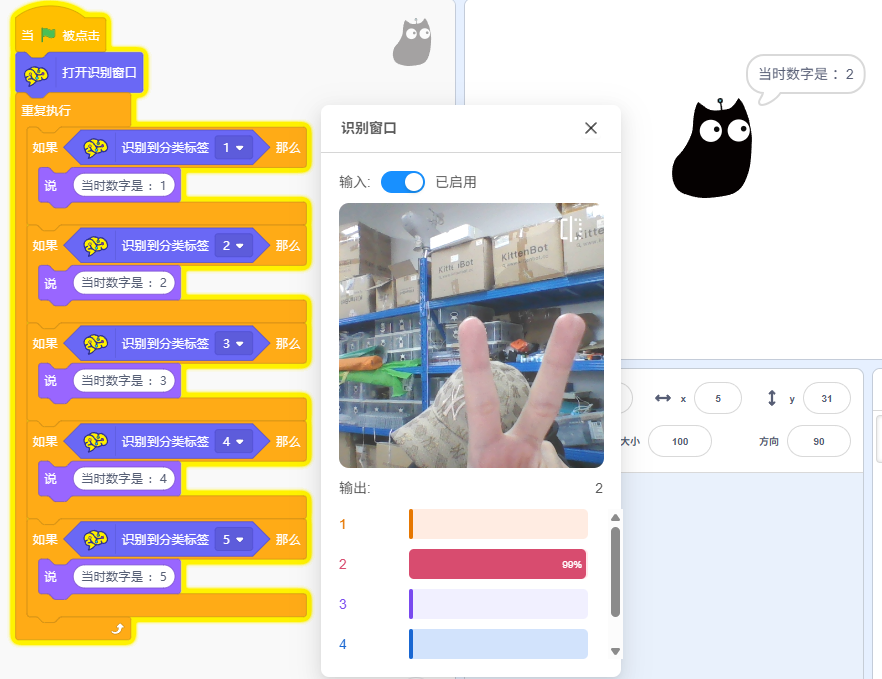
5.综合案例
使用图像识别,识别手指的数量,让角色说出数字。