姿态分类
关键技术:
- 姿态估计模型(PoseNet):用于检测人体关键点。
- 机器学习分类器:用于根据关键点特征进行分类。
处理环节:
- 数据收集:通过摄像头捕捉人体姿态 (交互环节)
- 特征提取:姿态估计模型识别并提取人体关键点(内部环节)
- 模型训练:将关键点数据输入机器学习分类器,训练模型以识别不同姿态(内部环节)
- 姿态预测:模型根据关键点数据实时识别新姿态 (交互环节)
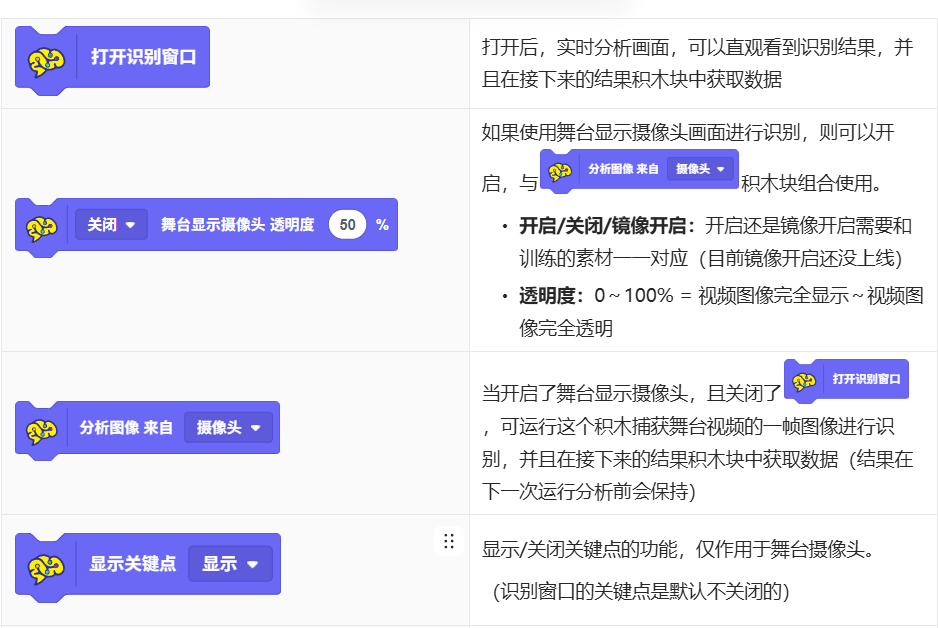
01 - 数据收集
接下来将尝试一个最简单的,只有2个分类(举手和不举手)的项目带同学们快速了解应用过程
- 首先理清我们需要制作的,是一个可以分辨人体姿态是否有举手的模型,1个分类叫做 “不举手”,另一个叫做 “举手”,接下来使用摄像头开始采集数据
- 采集分类“不举手”,尽量让素材图像的关键点数量统一,因为训练姿态模型时,关键点的坐标是重要因素。
所谓的关键点统一,大概理解为:
在摄像头里,人体的关节会被标注上一些点,就是用这些点的坐标关系去训练模型。如果同一个分类训练的点显示不全没关系,但不建议显示的点数量不一样(例如有的有手臂,有的没手臂)
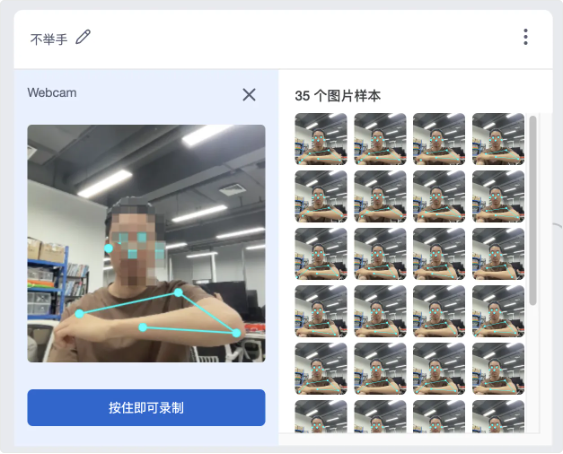
- 采集分类“举手”,我会在同一个场景下,在画面中举手,尽量让我的手部关节能够出现,并且状态可以自由一些,没必要每一张都录得完全一样的僵硬。
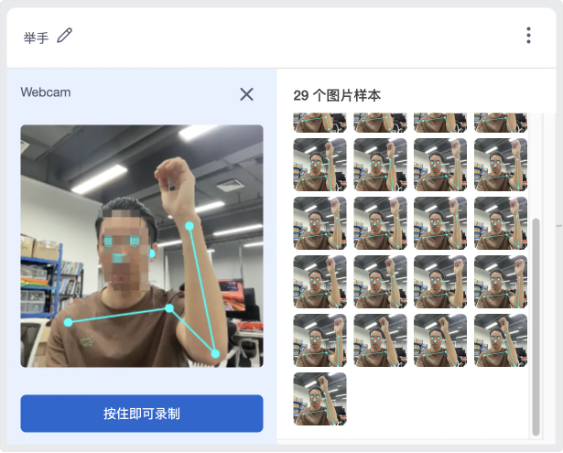
- 为了确保我的素材比较优质,我会检查一遍素材,并手动删掉几个没有关键点的“劣质”素材。

- 这样我们就拥有了2个分类,且有足够的素材,可以开始训练了(素材数量建议每种分类10个以上)
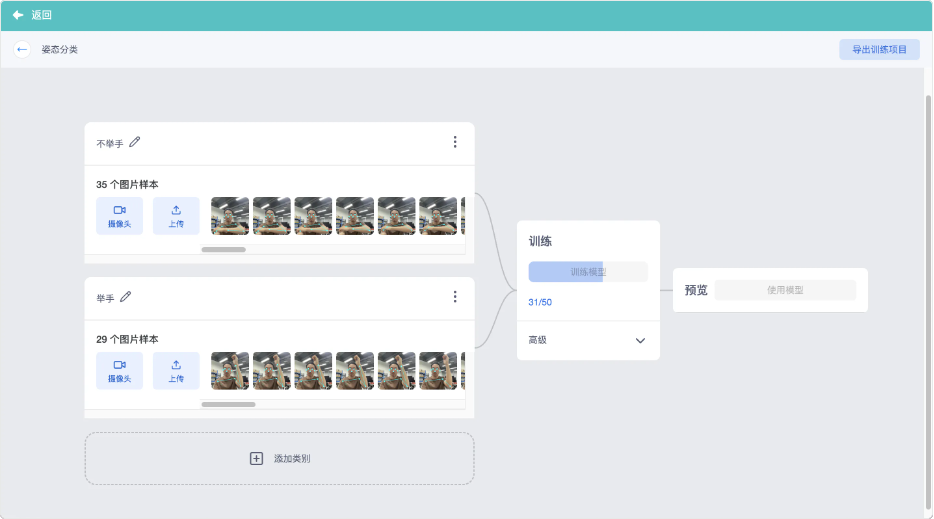
- 随着素材的数量多少,训练可能会花费一些时间,完成训练后在右侧可以体验训练识别结果
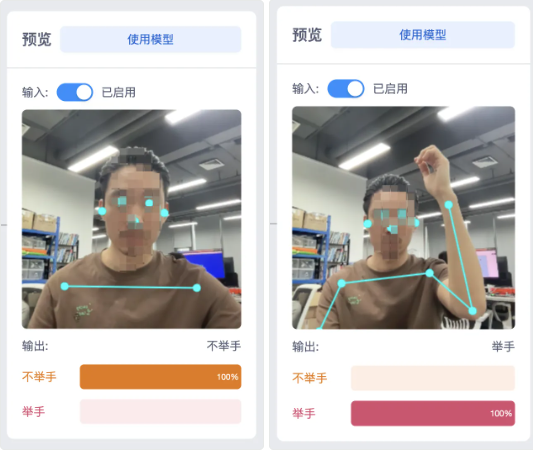
- 从上面的识别结果看来,非常完美。只要识别可信度在80%以上都数据成功的模型,我们可以点击 使用模型 将模型导出成积木块回到编程界面使用
通常分类的数量越多,可信度的标准可以适当降低,通过观察大概在60%以上,即可认为效果不错。
备注
注意,在使用模型这一步,如果你的当前作品之前就有其他的模型,那么会提示你,选择确认就会覆盖掉旧的,如果没保存记得保存。
02 - 姿态预测
开始图像预测前,先来认识一下相关积木块的功能